Publications
A collection of my research work.

Learning Human-Humanoid Coordination for Collaborative Object Carrying
Yushi Du*, Yixuan Li*, Baoxiong Jia†*, Yutang Lin, Pei Zhou, Wei Liang†, Yanchao Yang†, Siyuan Huang†
International Conference on Robotics and Automation (ICRA) 2026
COLA is a proprioception-only reinforcement learning approach that combines leader and follower behaviors within a single policy, enabling compliant human-humanoid collaborative carrying.


CLONE: Closed-Loop Whole-Body Humanoid Teleoperation for Long-Horizon Tasks
Yixuan Li*, Yutang Lin*, Jieming Cui, Tengyu Liu, Wei Liang†, Yixin Zhu†, Siyuan Huang†
Conference on Robot Learning (CoRL) 2025
CLONE is a whole-body teleoperation system that overcomes the limitations of decoupled upper- and lower-body control and open-loop execution.
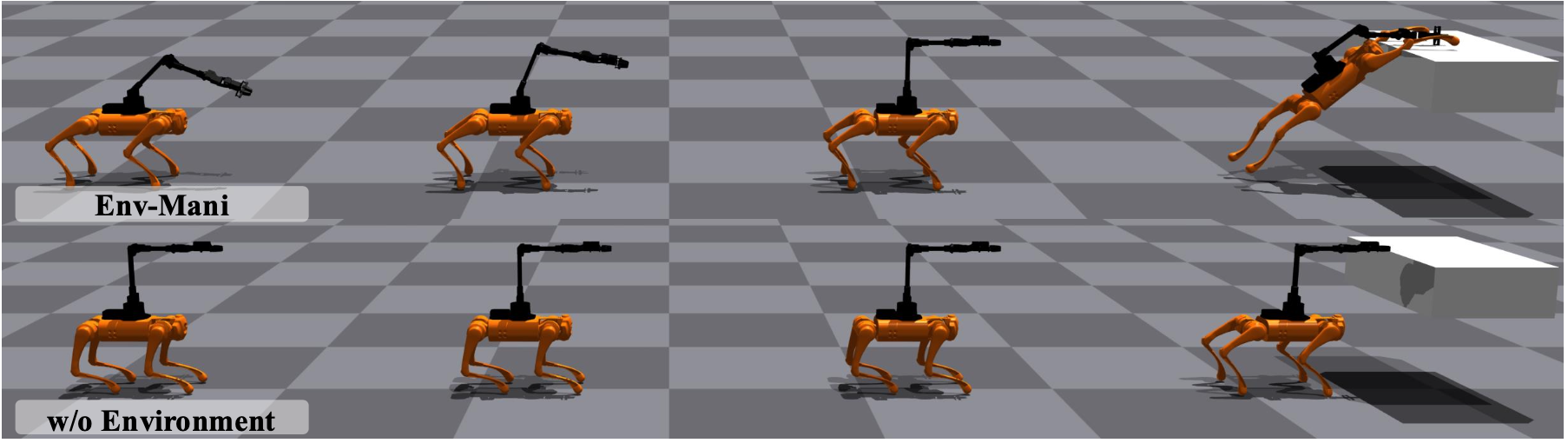
Env-Mani: Quadrupedal Robot Loco-Manipulation with Environment-in-the-Loop
Yixuan Li, Zan Wang, Wei Liang†
International Conference on Intelligent Robots and Systems (IROS) 2025
Env-Mani is a unified, learning-based loco-manipulation framework for quadrupedal robots that allows them to utilize the external environment as support to extend their workspace and enhance their manipulation capabilities.
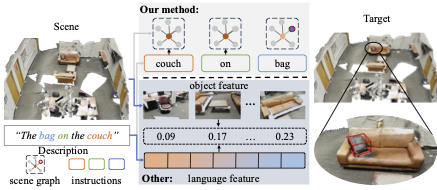
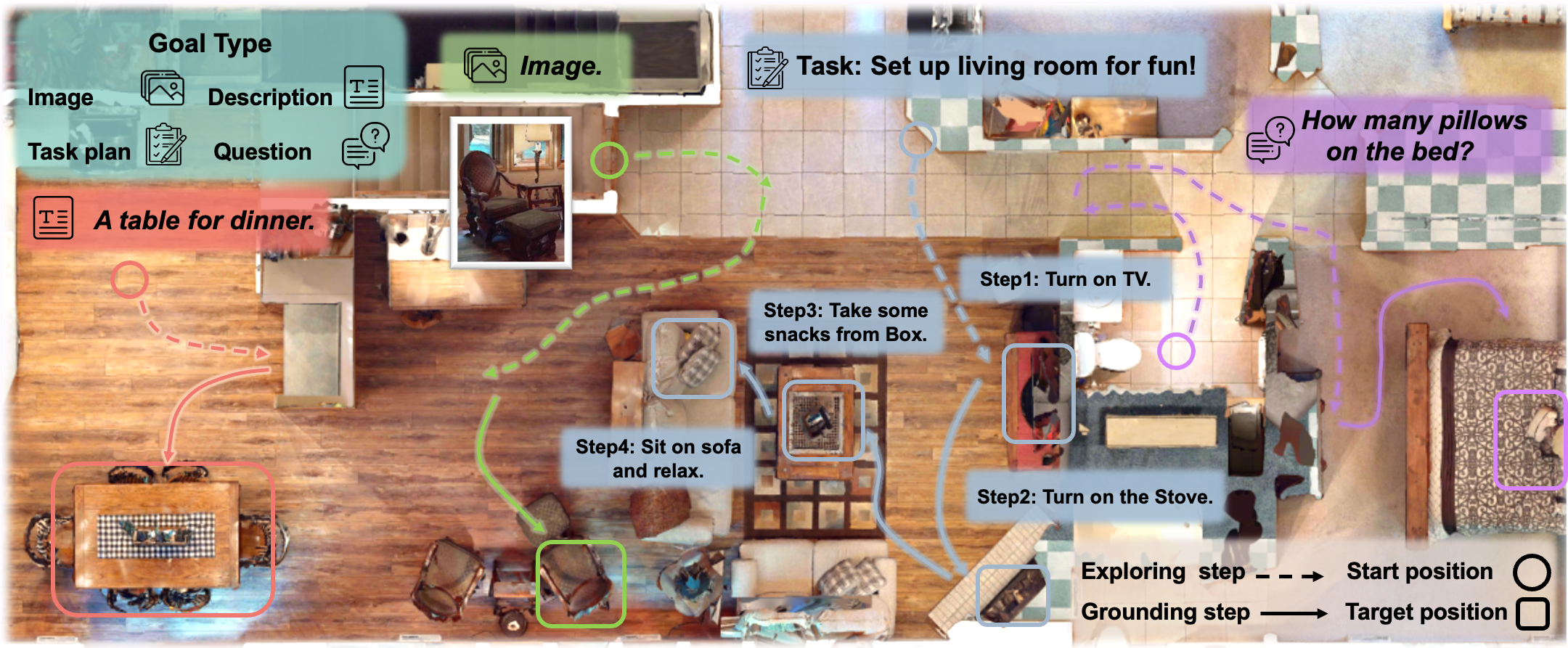
Move to Understand a 3D Scene: Bridging Visual Grounding and Exploration for Efficient and Versatile Embodied Navigation
Ziyu Zhu, Xilin Wang, Yixuan Li, Zhuofan Zhang, Xiaojian Ma, Yixin Chen, Baoxiong Jia, Wei Liang, Qian Yu, Zhidong Deng†, Siyuan Huang†, Qing Li†
International Conference on Computer Vision (ICCV) 2025
MTU3D is a unified framework that integrates active perception with 3D vision-language learning, enabling embodied agents to effectively explore and understand their environment.